Tool Performance
Evaluating the performance of fall risk assessment tools can be challenging since fall prevention programs in place within a hospital can obscure the true fall risk of patients, as interventions are already in place, preventing an unknown number of falls in patients at risk of fall.12 In addition, given a typical fall rate of approximately 2%, it could be expected that the Specificity and C-statistics for falls risk tools will be low in general. However, variation in performance has been evaluated in several studies, so it is reasonable to expect that a superior tool can be developed that will have a significantly positive impact on clinical practice and patient safety.
The JHFRAT is widely used across acute care hospital settings in the US and is said to be effective when combined with a comprehensive prevention protocol, including fall-prevention products and technologies. Several studies have evaluated the validity of the score, including sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV). Given the tool requires manual use, evaluation should also include the inter-rater reliability of the tool. This has been shown to be as high as 97.14% in one study.13 External validation studies of the JHFRAT have produced variable sensitivity and specificity results, but the area under the curve (AUC) shows consistency. The following table summarizes the results of three validation studies:
Study
Sensitivity
Specificity
AUC
69.0%
60%
0.71
26.5%
89.6%
0.69
25%
89%
0.67
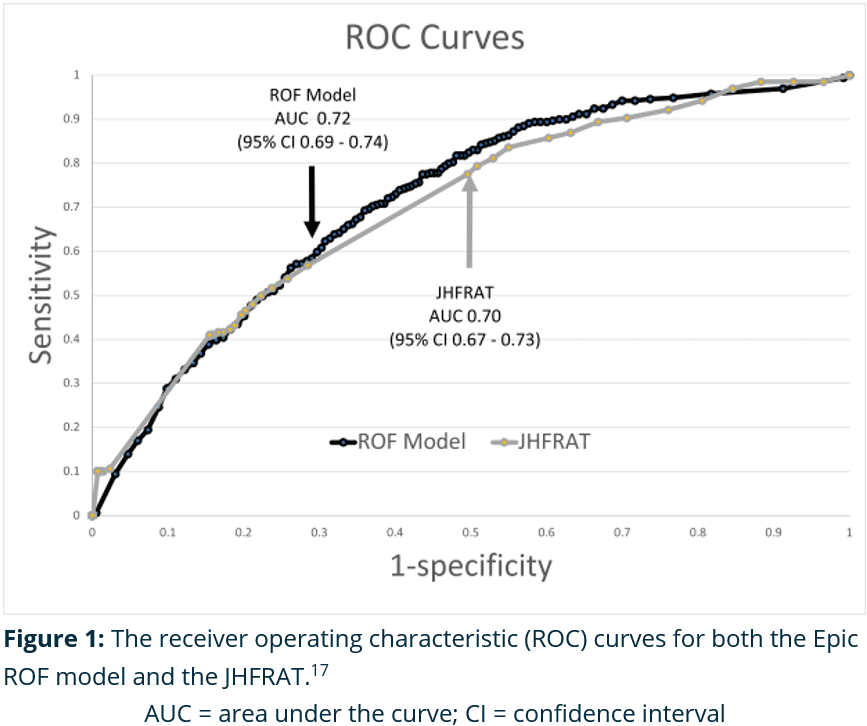
Since the introduction of the Epic ROF model, one validation study has been conducted comparing the performance and reliability of the ROF to the JHFRAT.17 In this study, the JHFRAT and Epic ROF were evaluated over 9 months, a period that included 35,709 patient encounters and 323 fall events. During this time, the ROF Model had a higher fall rate in the high-risk category (1.82% compared to 1.39%), and moderate-risk category (1.06% compared to 0.54%), but a similar fall rate in the low-risk category (0.33% compared to 0.35%). The following table is a summary of the validation findings of the high-risk categories for each tool.17
When the moderate and high-risk categories of the ROF model were combined an increased sensitivity of 81.8% was observed; however, this resulted in a decreased specificity of 48.6%, significantly increasing the false positive rate in practice.17
PPV
60.8%
69.7%
0.018
0.72
79.3%
49.2%
0.014
0.70
After development of the K-FRAS, a validation was conducted using a set of 100,000 patient records that included 385 fall events. For data analysis and validation, precision, recall, and F1 scores were evaluated.
Precision is also known as positive predictive value. In a high-precision model cases that the model does classify as positive are very likely to be correct. In this example, cases that a model deems high-risk for falls are fall cases.
Recall is equivalent to sensitivity. A model with high recall succeeds well in finding all the positive cases in the data.
The F1 score is the harmonic mean of the two. The F1 score is a better measure than accuracy in situations where there is significant imbalance in a data set. In the case of falls, it is expected that 98% of cases will not have a fall event, so a model could be considered accurate if it determined that no patient was at high-risk for falls. This would clearly be unhelpful clinically.
Like the validation study of the Epic ROF, the JHFRAT was used as a comparison for the K-FRAS as the JHFRAT was in use by the hospitals that provided the data. The results are displayed in the following table.
Precision
Recall
F1
100%
84%
0.9
50.4%
53.7%
0.41